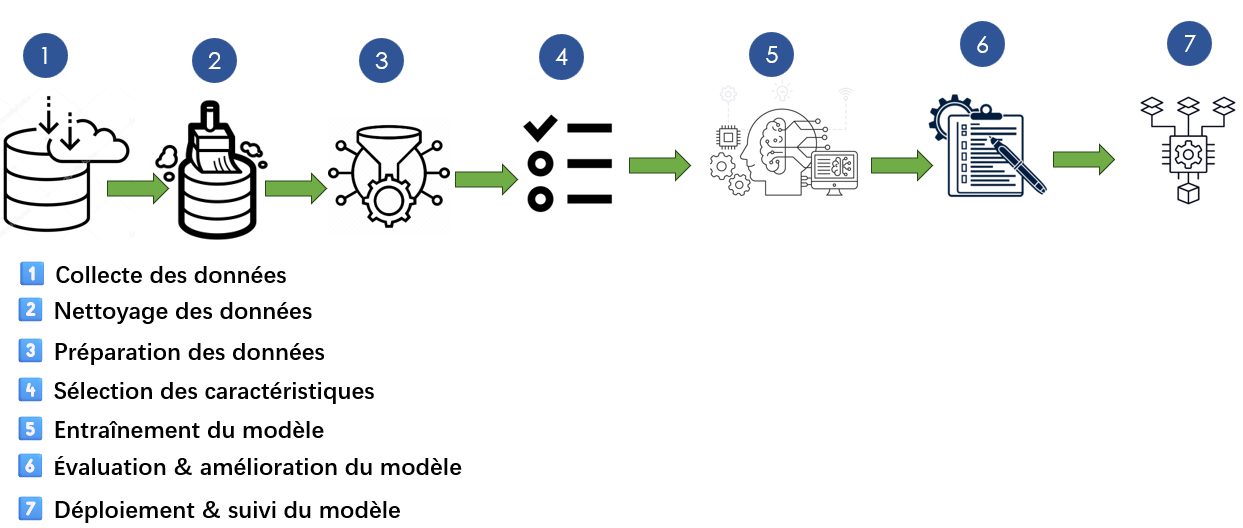
Un modèle d’intelligence artificielle ne vaut que par la qualité des données qu’il reçoit. Avec notre service de préparation de données pour le machine learning, nous construisons pour vous un pipeline complet qui nettoie, transforme, encode, équilibre et structure vos datasets.
Notre approche garantit un input optimal pour vos algorithmes, qu’ils soient de classification, régression, NLP ou vision par ordinateur. Vos modèles sont ainsi plus performants, plus robustes et mieux généralisés.
➡️ Ce que vous obtenez :
- Datasets nettoyés, équilibrés, normalisés
- Réduction de biais, des outliers et des valeurs manquantes
- Formats compatibles avec tous les frameworks (TensorFlow, PyTorch, scikit-learn, etc.)
- Pipeline reproductible et automatisé
🎯 Idéal pour les data scientists, équipes IA, ou projets de proof-of-concept.
👉 Préparez vos données pour des modèles puissants. Contactez-nous pour un audit gratuit et un pipeline sur mesure.